


Spring Webflux, Reactive Kafka, Cassandra. Complete Reactive Spring Apps
Consume and produce message to topics using Spring Webflux and Reactive Kafka.


Introduction
Building modern, scalable web applications requires technologies that can handle large amounts of data and high volumes of traffic. The combination of Spring WebFlux, Reactive Kafka, and Cassandra can provide a powerful stack for building such applications. In this blog post, let's explore how to integrate these technologies and build a reactive, event-driven system.
The Architecture of the Apps
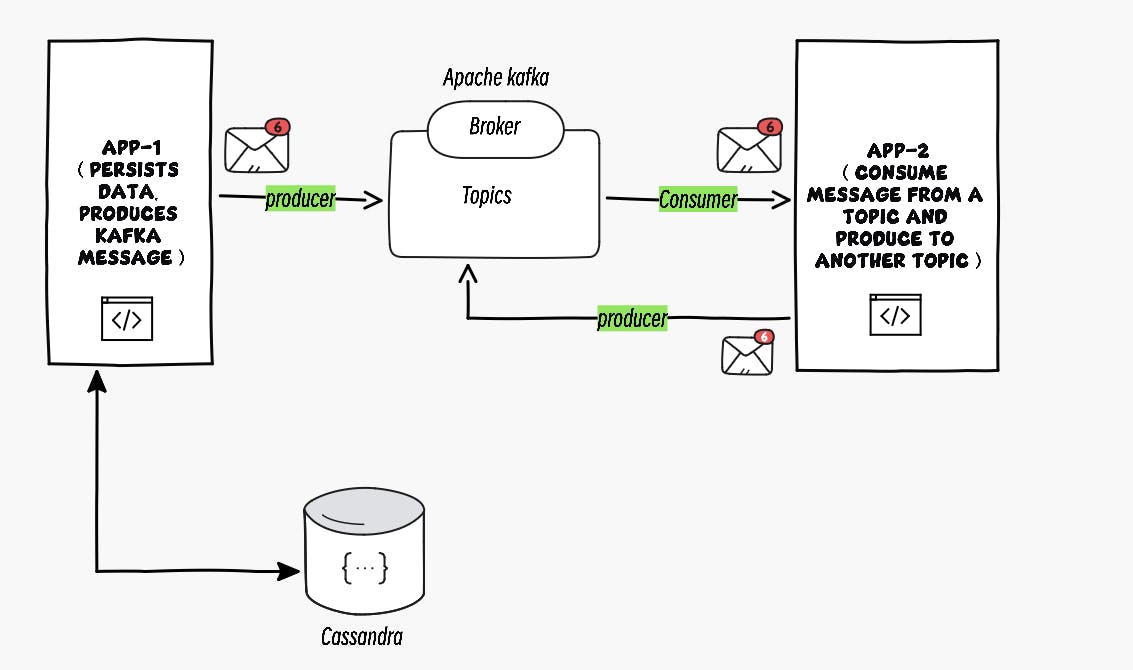
We'll need:
Java > 8.
Cassandra (you can use AstraDB like me if you don't want to install it locally)
Configure Kafka on your machine:
Download the binary file and extract it.
Open the command prompt in the extracted folder.
Start Zookeeper:
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
Start Kafka: In another command prompt window
.\bin\windows\kafka-server-start.bat .\config\server.properties
Create topics app_updates & emp_updates: In another command prompt window
.\bin\windows\kafka-topics.bat --create --topic app_updates--bootstrap-server localhost:9092
.\bin\windows\kafka-topics.bat --create --topic emp_updates--bootstrap-server localhost:9092
For listening to a topic directly from command prompt
.\bin\windows\kafka-console-consumer.bat -bootstrap-server localhost:9092 -topic
topic_name. Replace topic_name with your topic name(Eg: app_updates, emp_updates)
Github links for the Apps
App-1: https://github.com/utronics/Kafka-App-1
App-2: https://github.com/utronics/Kafka-App-2
App-1
Dependencies required:
Add the following dependencies while generating the project using Spring Initializer.

Additionally, add the following dependencies in your pom.xml
<dependency>
<groupId>io.projectreactor.kafka</groupId>
<artifactId>reactor-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-webflux-core</artifactId>
<version>1.6.14</version>
</dependency>
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-webflux-ui</artifactId>
<version>1.6.14</version>
</dependency>
The first dependency, io.projectreactor.kafka:reactor-kafka, is the reactive Kafka client library that provides a set of abstractions for building reactive Kafka consumers and producers.
The next two dependencies are for Swagger.
I am using a previous app I build which performs CRUD operations to the AstraDb-Cassandra database and added the functionality to produce Kafka messages to a topic. (check out the previous app blog here https://utronics.hashnode.dev/connect-spring-webflux-with-astradb-cassandra-database-crud-operations)
Application properties
spring:
kafka:
bootstrap-servers: localhost:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
data:
cassandra:
keyspace-name:
username: #Client ID - get from Token
password: #Client Secret - get from Token
schema-action: create-if-not-exists
request:
timeout: 10s
connection:
connect-timeout: 10s
init-query-timeout: 10s
datastax.astra:
secure-connect-bundle: #Path of the connect bundle zip file.
astra.db:
id: #Datacenter ID
region: #region
keyspace: #keyspace-name
application.token: #Token
PRODUCER_TOPIC: app_updates
Config class
@Configuration
public class EmpKafkaProducerConfig {
@Bean
public SenderOptions<String, Employee> producerProps(KafkaProperties kafkaProperties) {
return SenderOptions.create(kafkaProperties.buildProducerProperties());
}
@Bean
public ReactiveKafkaProducerTemplate<String, Employee> reactiveKafkaProducerTemplate(
SenderOptions<String, Employee> producerProps) {
return new ReactiveKafkaProducerTemplate<>(producerProps);
}
}
The producerProps method does some behind-the-scenes work. It creates a set of properties, known as producerProps, that defines how the Kafka producer should behave. These properties include things like which server to connect to, how to serialize the data, and more. It will take into consideration the kafka properties mentioned in application.properties file
The reactiveKafkaProducerTemplate method does something similar, but it sets up a special template that wraps around the Kafka producer. This template provides an easier and more reactive way to send messages to Kafka.
@Component
@Slf4j
public class EmpKafkaProducer {
@Value(value = "${PRODUCER_TOPIC}")
private String topic;
@Autowired
private ReactiveKafkaProducerTemplate<String, Employee> reactiveKafkaProducerTemplate;
public void sendMessages(Employee employee) {
log.info("send to topic={}, {}={},", topic, Employee.class.getSimpleName(), employee);
reactiveKafkaProducerTemplate.send(topic, String.valueOf(employee.getId()), employee)
.doOnSuccess(senderResult -> log.info("sent {} offset : {}",
employee,
senderResult.recordMetadata().offset()))
.subscribe();
}
}
The reactiveKafkaProducerTemplate.send method is used to send the message to the Kafka topic. It specifies the topic, a key (converted to a string using the employee's ID), and the employee object as the value.
This method is being called from the controller for update and insert endpoints.
APP 2:
Properties
server:
port: 8081
spring:
kafka:
bootstrap-servers: localhost:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
consumer:
group-id: group-update-service
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
properties:
spring:
json:
use:
type:
headers: false
value:
default:
type: com.updateservice.model.EmployeeRequest
#
CONSUMER_TOPIC: app_updates
EMP_UPDATES_TOPIC: emp_updates
The consumer subsection configures the Kafka consumer. It sets the consumer group ID, which is used to coordinate the consumption of messages among multiple consumers. It also specifies the auto-offset-reset property as "earliest", meaning that the consumer will start consuming from the earliest available offset if no committed offset is available for a partition.
The key-deserializer and value-deserializer properties specify the deserializers to be used for the key and value.
By setting spring.json.use.type.headers to false, it disables the inclusion of type information in JSON headers. Additionally, it specifies the default type to be used for deserializing JSON values of the EmployeeRequest class.
Config:
@Configuration
@Slf4j
public class EmpKafkaConsumerConfig {
@Bean
public ReceiverOptions<String, EmployeeRequest> kafkaReceiverOptions(@Value(value = "${CONSUMER_TOPIC}") String topic,
KafkaProperties kafkaProperties) {
ReceiverOptions<String, EmployeeRequest> basicReceiverOptions = ReceiverOptions.create(kafkaProperties.buildConsumerProperties());
return basicReceiverOptions.subscription(Collections.singletonList(topic))
.addAssignListener(partitions -> log.info("onPartitionsAssigned {}", partitions))
.addRevokeListener(partitions -> log.info("onPartitionsRevoked {}", partitions));
}
@Bean
public ReactiveKafkaConsumerTemplate<String, EmployeeRequest> reactiveKafkaConsumerTemplate(
ReceiverOptions<String, EmployeeRequest> kafkaReceiverOptions) {
return new ReactiveKafkaConsumerTemplate<>(kafkaReceiverOptions);
}
}
The kafkaReceiverOptions method creates a bean called kafkaReceiverOptions that provides the configuration options for the Kafka consumer. It takes the topic name and Kafka properties as inputs, from properties file.
The reactiveKafkaConsumerTemplate method creates a bean named reactiveKafkaConsumerTemplate that represents a reactive wrapper around the Kafka consumer. It takes the kafkaReceiverOptions bean as an input and creates a new instance of ReactiveKafkaConsumerTemplate using the provided options.
@Configuration
public class EmpKafkaProducerConfig {
@Bean
public SenderOptions<String, EmployeeRequest> producerProps(KafkaProperties kafkaProperties) {
return SenderOptions.create(kafkaProperties.buildProducerProperties());
}
@Bean
public ReactiveKafkaProducerTemplate<String, EmployeeRequest> reactiveKafkaProducerTemplate(
SenderOptions<String, EmployeeRequest> producerProps) {
return new ReactiveKafkaProducerTemplate<>(producerProps);
}
}
Service:
@Service
@Slf4j
public class EmpKafkaConsumerService {
@Autowired
private EmpKafkaProducerService empKafkaProducerService;
@Autowired
private ReactiveKafkaConsumerTemplate<String, EmployeeRequest> reactiveKafkaConsumerTemplate;
@Value(value = "${EMP_UPDATES_TOPIC}")
private String empTopic;
public Flux<EmployeeRequest> consumeAppUpdates() {
log.info("In consumeAppUpdates()");
return reactiveKafkaConsumerTemplate
.receiveAutoAck()
.doOnNext(consumerRecord -> log.info("received key={}, value={} from topic={}, offset={}",
consumerRecord.key(),
consumerRecord.value(),
consumerRecord.topic(),
consumerRecord.offset())
)
.map(ConsumerRecord::value)
.doOnNext(employeeRequest -> {
log.info("successfully consumed {}={}", EmployeeRequest.class.getSimpleName(), employeeRequest);
empKafkaProducerService.sendMessages(employeeRequest,empTopic);
})
.doOnError(throwable -> log.error("something went wrong while consuming : {}", throwable.getMessage()));
}
@PostConstruct
public void init() {
log.info("In init()");
this.consumeAppUpdates().subscribe();
}
}
The init method is annotated with @PostConstruct, which means it will be executed after the object is constructed and its dependencies are injected.
Inside the init method, the consumeAppUpdates method is called, and the resulting Flux is subscribed to. This initiates the consumption of messages from the Kafka topic.
In consume consumeAppUpdates methods we are calling empKafkaProducerService.sendMessages(employeeRequest,empTopic); which sends message to emp_updates topic.
@Service
@Slf4j
public class EmpKafkaProducerService {
@Autowired
private ReactiveKafkaProducerTemplate<String, EmployeeRequest> reactiveKafkaProducerTemplate;
public void sendMessages(EmployeeRequest employeeRequest, String topic) {
log.info("send to topic={}, {}={},", topic, EmployeeRequest.class.getSimpleName(), employeeRequest);
reactiveKafkaProducerTemplate.send(topic, String.valueOf(employeeRequest.getId()), employeeRequest)
.doOnSuccess(senderResult -> log.info("sent {} offset : {}", employeeRequest,
senderResult.recordMetadata().offset()))
.subscribe();
}
}
Result:
Console consumer:
Messages are produced to app_updates topic by App1
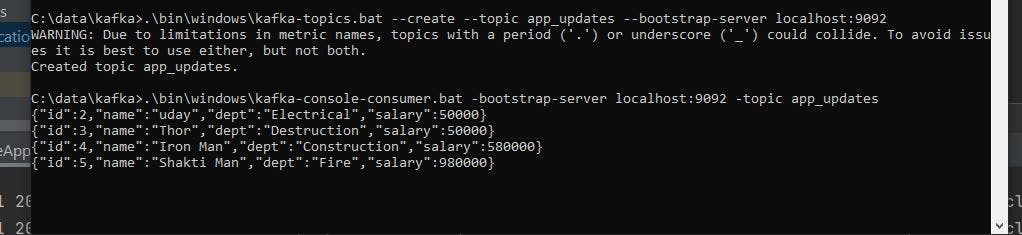
The messages from the app_updates topic are consumed by App2 and produced again to the emp_updates topic
